What Are People Searching On Serendipity?
It's been almost two months since Serendipity launched! Since then, we have had over 20,000 searches, helping people find suggestions for movies, books, and whatever else they want to find.
In this blog post, we'll do a quick dive of the data to see what people are searching for.
How Serendipity Works
First, a quick overview of how Serendipity works. You phrase what you're looking for in a natural language query, like movies that explore near future technologies and their implications on society, and our AI backend parses it to find items related to the query. Feel free to get super specific or super abstract with the query text, just make sure to use good grammar and spelling.
There are currently three different search categories: movies, books, and anything else. The search/ranking algorithm is mostly the same, except that we try to stay within the selected category, so movies will only return results that are movies and ignore books and vice versa. Additionally, the user interface is different.
Depending on what you're interested in, you should select the appropriate category for your search.
Breakdown Amongst Categories
Movies gets over 10x the number of queries that books do. This is possibly because all the examples in the carousel in the landing page are movies, so this predisposes people to searching for movies (clicking on an item takes you to that particular query).
As a result of this, I've been focusing most of my development effort towards improving the UI for the movies category.
Are you someone who frequently looks for book recommendations? If so, we'd love to hear from you! You can email me or drop into the product feedback discord.
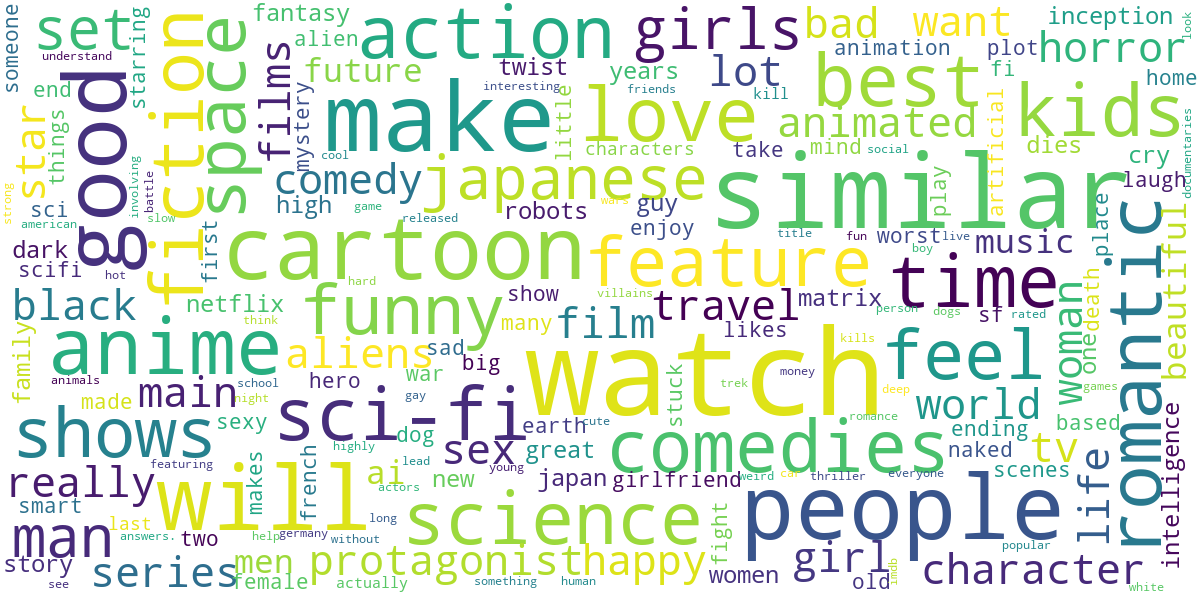
Wordcloud
Here are the search query terms rendered as a word cloud (with stop words removed).
Movies
Books
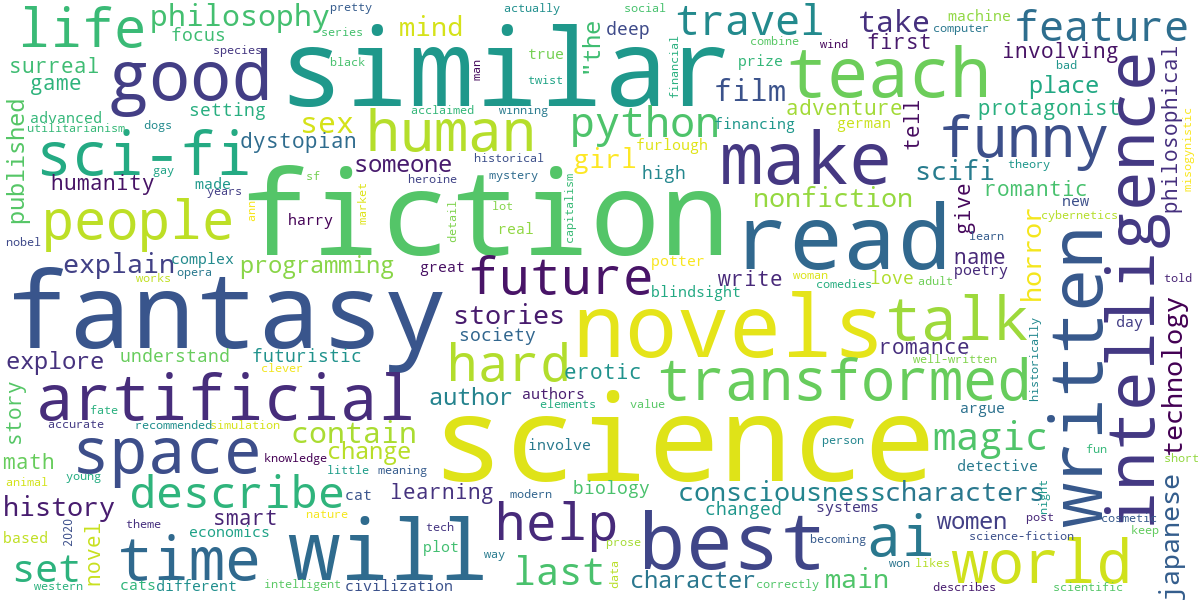
From this, it looks like the most common terms are genre descriptors. Also, the "similar" keyword means that another common search mode is to get recommendations from known examples you already like, using queries like movies similar to fight club.